AMUQuiz : La plateforme de quiz adaptatif par DREAM-U
Ce document décrit globalement les motivations et le fonctionnement de la plateforme d’apprentissage adaptatif développée au sein d’AMU et dans le cadre du projet DREAM-U. Plus précisément, il donne une vue d’ensemble sur le projet en termes de vision, d’expérience utilisateur et d’architecture logicielle, en particulier pour la première version (prévue pour avril).
Note sur les citations et les références (vous pouvez ignorer cette section si vous avez l’habitude du style de citation des articles scientifiques) :
- Ce document utilise le style de citation APA (American Psychological Association). Si vous n’êtes pas familier des articles académiques, cette approche pour citer ses sources peut sembler déroutante au premier abord. Pourquoi ne pas utiliser seulement de simples liens web par exemple ? D’une part, certaines références (notamment les articles scientifiques ou les livres) ne sont pas toujours accessibles directement par des liens. D’autre part, cette approche a un certain nombre d’avantages. On regroupe clairement toutes les références du document à un endroit, on peut facilement retrouver les références même en lisant la version papier, et on a un standard clair dans lequel il est très facile de s’y retrouver une fois habitué. Pour plus d’informations, vous pouvez lire une présentation des styles de citation (Debret, 2015). Lorsque c’est possible, comme ici, des liens directs sont conservés dans le texte pour rendre la lecture en ligne plus fluide.
- Au regard de la situation actuelle du manque d’accès libre aux publications scientifiques (Francis, 2020), vous pourriez rencontrer quelques difficultés en tentant d’obtenir les articles scientifiques référencés. Dans ce cas, il peut être utile de demander de l’aide à quelqu’un ayant l’habitude, ou de s’intéresser à Sci-Hub (« Sci-Hub », 2011). Notez aussi que le présent document référence également des pages web et des vidéos qui sont, pour leur part, facilement accessibles en cliquant sur les liens.
1 Mission générale
L’objectif général est d’améliorer l’apprentissage et la réussite des étudiants par le biais d’une plateforme web leur proposant un entraînement personnalisé, principalement sous forme de quiz adaptatifs : le système sélectionne automatiquement les questions adaptées pour le niveau de l’étudiant.
Une plateforme qui se veut moderne, épurée, immersive, innovante et solidement basée sur la recherche en pédagogie.
1.1 Méthode
Plutôt que de présenter un cahier des charges classique, la proposition est ici de suivre le modèle de développement participatif agile adopté avec succès par de nombreux projets logiciels comme Node.js (OpenJS Foundation, 2021), Rust (Matsakis & Klock, 2014) et son développement par RFCs (Rust Languagee Team, 2021), ainsi que de nombreux autres. Si cette approche vous semble peu rigoureuse, remarquez que le cahier des charges classique amène souvent à un développement de type “waterfall” (« Modèle en cascade », n.d.), peu flexible et peu réactif à l’émergence inattendue de nouveux besoins ou de nouvelles technologies.
Dans ce cadre de développement participatif, les changements à apporter sont discutés entre les participants au projet. Que vous soyez étudiant, enseignant, développeur, administrateur système ou autre, vos idées et vos avis sont les bienvenus. Les décisions découlent assez naturellement de la mission que se donne le projet et de ses valeurs. La mission détermine l’objectif, et les valeurs permettent, lorsque plusieurs solutions sont disponibles pour atteindre un même objectif, de clarifier la solution à privilégier : la plupart du temps, une solution collera mieux aux valeurs que les autres.
La définition explicite de ces valeurs joue un rôle essentiel puisqu’en plus d’éclairer les décisions, elle rend le projet plus résilient au risque de “value drift” (quand les valeurs initiales et souvent implicites d’un projet dérivent pour servir des intérêts spécifiques). Cela évite que les intérêts privés d’une personne ou d’une entité pèsent de façon disproportionnée dans les décisions. Concrètement pour ce projet développé au sein d’AMU, de nombreux interlocuteurs sont invités à participer (étudiants, enseignants, personnel DREAM-U, administrateurs système, présidence, développeurs…). Et leurs intérêts ne sont pas toujours alignés.
1.2 Valeurs
Étant au début du projet, les valeurs que nous souhaitons porter sont à définir, à discuter et à clarifier. Voici une suggestion de point de départ :
- Respect de l’humain : Contribuer à améliorer la condition des utilisateurs du système.
- Inclusivité : Accueillir et respecter les différents points de vue. Écouter les personnes qui souhaitent participer.
- Centration sur l’expérience utilisateur : Prendre des décisions qui améliorent l’expérience globale des utilisateurs.
- Ergonomie : Maximiser l’ergonomie du système (minimiser le temps de chargement des pages, rendre les tâches intuitives, l’interface agréable…).
- Recherche d’efficacité : Tenter autant que possible d’améliorer les algorithmes et les solutions technologiques utilisées pour aider les étudiants dans leurs apprentissages et leur sentiment d’efficacité personnelle.
- Respect de la recherche scientifique : Intégrer concrètement, quand c’est possible, les résultats de la recherche en sciences de l’apprentissage. Prendre les décisions en suivant la recherche plutôt qu’une opinion.
- Modernité et innovation : Sans tomber dans les pièges du hype, pencher vers des choix techniques modernes et adaptés aux objectifs, et tenter des solutions innovantes.
- Facilité de maintenance et d’évolution : Faciliter la tâche des administrateurs système et des contributeurs potentiels (procédure d’installation simple et claire, documentation claire et exhaustive).
- Pragmatisme et no bullshit : Faire des choix concrètement et directement utiles, et quand c’est possible, proposer des démonstrations fonctionnelles plutôt que des discours.
- Éthique des algorithmes : Les algorithmes d’intelligence artificielle sont puissants et peuvent apporter beaucoup de bien, mais aussi causer de lourds dégâts : prolifération des fake news, des théories du complot, boucles de rétroaction et bulles de filtre, génocide des Rohingyas (« Génocide des Rohingyas : le mea culpa de Facebook », 2018), robots tueurs (Campaign to Stop Killer Robots, 2020)… Bien sûr, l’échelle est ici différente, mais il semble tout de même essentiel d’avoir une réflexion réelle sur l’éthique des algorithmes et leurs risques potentiels, avant même leur déploiement, et d’être attentif et réactif à l’émergence d’effets inattendus.
- Clarté : Communiquer clairement autour du projet, des intentions et des décisions. Éviter les ambiguïtés.
2 Motivations pour la création d’un système d’apprentissage adaptatif
2.1 Psychologie de l’apprentissage
Lorsque l’on souhaite offrir un environnement d’apprentissage efficace, il existe un certain nombre de besoins chez les apprenants auxquels il est utile de répondre. L’idée ici n’est pas d’être exhaustif sur les connaissances scientifiques dans le domaine des apprentissages, mais simplement de poser quelques repères. Ces repères pourront nous servir de guide dans nos réflexions d’amélioration de la plateforme. Les approches techniques concrètes qu’on propose d’adopter pour suivre ces repères sont précisées plus loin dans ce document, dans la section décrivant les algorithmes.
2.1.1 Difficulté adaptée, avec la zone proximale de développement
Lorsqu’on apprend, il est bien utile de se confronter à des défis adaptés à notre niveau. On peut sentir intuitivement qu’une tâche trop facile amène à de l’ennui, alors qu’une tâche trop difficile amène à un sentiment d’échec, une impression d’insurmontable. Cet effet dans le domaine de l’apprentissage a été formalisé dans les années 1930 par Lev Vygotski, avec le concept de zone proximale de développement (Vygotski, 2019; « Zone proximale de développement », n.d.). Plus précisément, ce qui est dans la zone proximale de développement est ce qui est atteignable avec de l’aide extérieure (fig. 1).

Cette aide extérieure peut être un tuteur ou un enseignant, mais pas nécessairement : ça peut aussi être un livre, un pair, un site web… En tout cas, pour qu’une personne avance efficacement dans ses apprentissages, il est essentiel de lui donner accès à des tâches dont la difficulté correspond à sa zone proximale de développement. D’ailleurs, depuis Vygotski, d’autres études ont bien sûr confirmé l’importance de cette “difficulté désirable” dans l’apprentissage, et on peut aujourd’hui en observer les corrélats au niveau de l’activité cérébrale (Lin et al., 2011).
2.1.2 Effets émotionnels
Une autre part importante pour la qualité de l’apprentissage est le domaine émotionnel. Intuitivement, on peut percevoir que si vous êtes préoccupé, vous aurez du mal à apprendre efficacement. C’est l’effet inhibiteur du stress sur la mémorisation, qui est bien entendu confirmé par la littérature scientifique (Schwabe & Wolf, 2010). D’autre part, si vous êtes “intrinsèquement” motivé (le sujet vous intéresse, ou la tâche a du sens dans votre vie, par exemple), vous apprendrez plus efficacement que si vous révisez à cause d’une contrainte extérieure, pour obtenir une note par exemple. Dans le domaine, on parle de l’effet bénéfique de la motivation intrinsèque (en opposition à la motivation extrinsèque), lui aussi bien étudié (Cerasoli, Nicklin, & Ford, 2014).
Si vous croyez en votre capacité à réaliser une tâche, vous avez de meilleures chances d’effectivement la réaliser. Cette croyance, Bandura l’a appelée le “sentiment d’efficacité personnelle”, ou “auto-efficacité” (« Auto-efficacité », n.d.; Bandura, 1977). Ce concept est maintenant bien connu et il est établi qu’un sentiment d’auto-efficacité élevé améliore en général l’apprentissage et les performances (Joo, Bong, & Choi, 2000; Stajkovic & Luthans, 1998). L’auto-efficacité est cependant une bête complexe ! Quand on va dans les détails, il arrive notamment que l’apprentissage et la performance soient en fait correlés négativement avec le sentiment d’auto-efficacité (Vancouver & Kendall, 2006). Un excès de confiance s’avére délétère (on en parle davantage plus bas)… D’autre part, le sentiment d’efficacité personnel a un caractère auto-réalisateur : réussir une tâche augmente mon sentiment d’auto-efficacité, ce qui augmente la probabilité que je réussisse la tâche suivante, etc. De même, une malencontreuse série d’échecs peut avoir un effet dévastateur sur la capacité d’apprentissage d’une personne… C’est notamment pourquoi il est si important de permettre aux apprenants de faire l’expérience régulière de la réussite, notamment en sélectionnant des tâches adaptées.
Outre cela, on sait aussi que le fait d’éprouver du plaisir pendant l’apprentissage améliore les performances (Giannakos, 2013), et que l’ennui les dégrade (Tze, Daniels, & Klassen, 2016). On sait également que pour devenir compétent ou expert, de nombreux échecs préalables sont généralement nécessaires, et que la gestion affective de ces échecs, pour persévérer malgré eux, est donc cruciale (Burleson & Picard, 2004).
2.1.3 Répétition espacée
Une méthode simple et efficace pour améliorer la mémorisation et l’apprentissage en général est la répétition espacée. L’idée est simple : il existe une courbe naturelle de l’oubli, que nous connaissons depuis l’étude pionnière d’Ebbinghaus (1885), représentée dans la fig. 2.
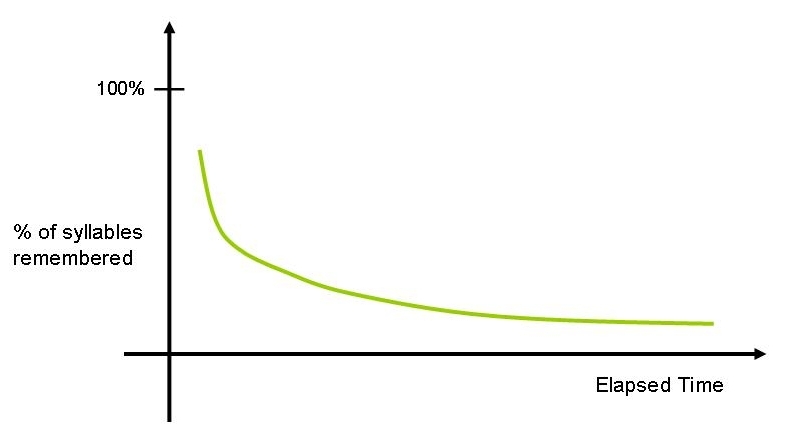
Partant de là, on peut se servir intelligemment de cette courbe, car à chaque fois qu’une information est révisée, la pente de la courbe de l’oubli est ralentie. Il suffit alors de réviser une information de façon répétée, en augmentant progressivement les intervalles de révision, pour quasiment garantir une rétention efficace de l’information. C’est la répétition espacée (fig. 3).
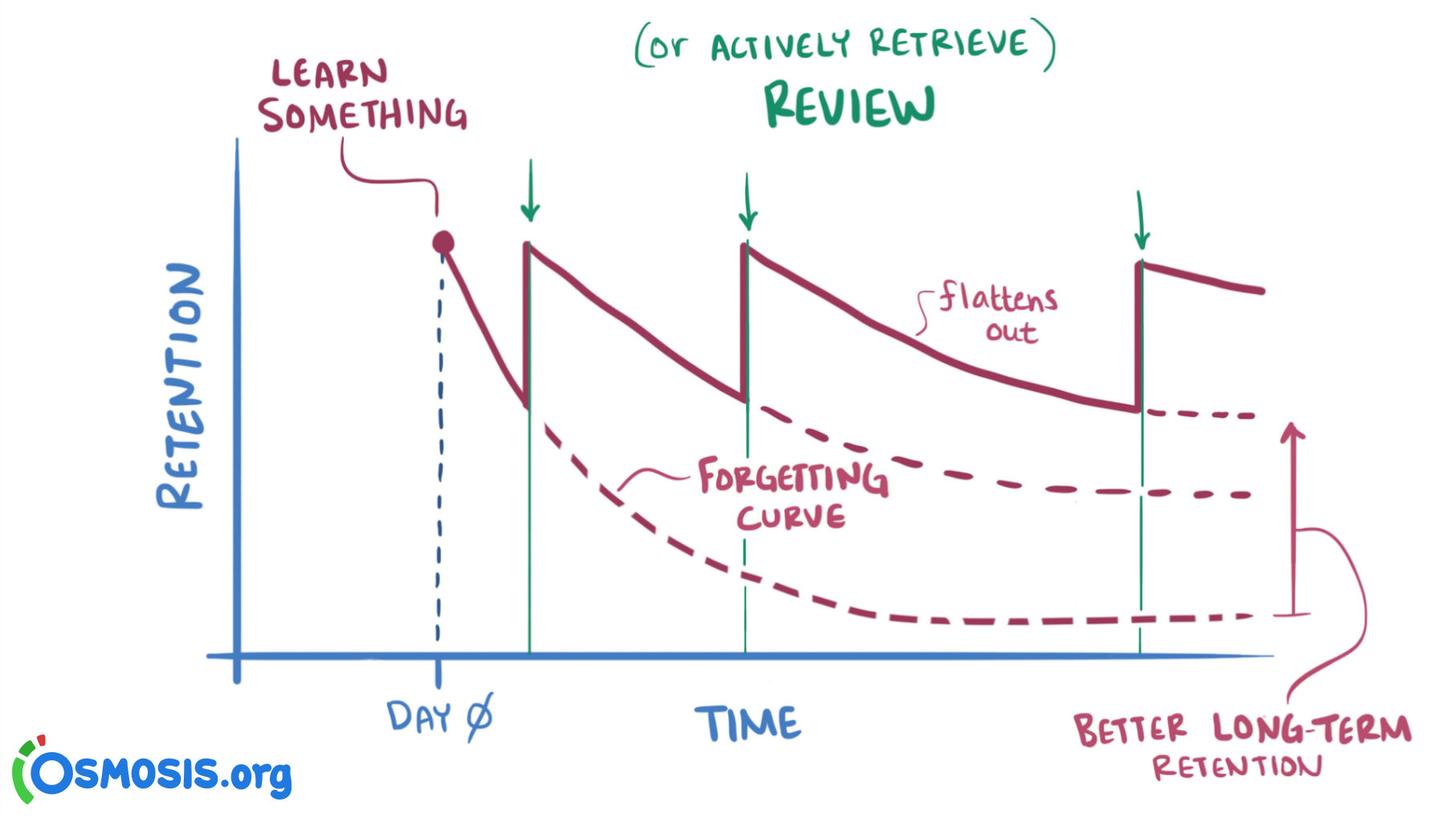
Les études scientifiques confirment que la répétition espacée améliore l’apprentissage (Kang, 2016; Tabibian et al., 2019). Aujourd’hui, des applications libres comme Anki (Elmes, 2011), massivement populaire chez les étudiants de médecine aux États-Unis, sont disponibles pour utiliser efficacement ce trait naturel de notre mémorisation.
2.1.4 Pratique entrelacée
Une autre technique puissante pour optimiser l’apprentissage, mais moins connue, est de favoriser la pratique “entrelacée”. Là aussi, l’idée est simple : si je veux m’entraîner sur les matières A, B et C, j’ai plusieurs approches possibles. Si j’ai neuf “opportunités” de révision dans le temps, je pourrais suivre la séquence A-A-A-B-B-B-C-C-C. C’est l’approche par blocs. Mais je pourrais aussi suivre une séquence du type A-B-C-A-B-C-A-B-C. C’est ce qu’on appelle l’entraînement entrelacé. C’est un peu plus difficile cognitivement, à cause de tous les changements de contexte requis par ce style de révision, mais cette difficulté fait justement partie de la “difficulté désirable” dans l’apprentissage. C’est une difficulté utile, qui développe la flexibilité cognitive et qui favorise aussi la création de liens entre les différentes matières. La littérature montre bien que l’approche entrelacée est plus efficace que l’approche par blocs (Lin et al., 2011; Rohrer, Dedrick, & Stershic, 2015; Taylor & Rohrer, 2009).
En l’état, on pourrait formuler une critique concernant l’efficacité de cette approche : en comparant les deux séquences A-A-A-B-B-B-C-C-C et A-B-C-A-B-C-A-B-C, on remarque que le simple fait de passer en pratique entrelacée crée plus ou moins les conditions de répétition espacée dont on a parlé plus haut. On peut donc se demander si l’effet bénéfique de l’entrelacement n’est pas simplement dû au fait qu’on ajoute de la répétition espacée comme “effet secondaire”. C’est une question qu’ont investiguée Taylor & Rohrer (2009), et ils ont montré qu’il y a bien un effet bénéfique spécifique de l’entrelacement, indépendamment de l’effet de la répétition espacée.
2.2 L’excès de confiance tue
“L’excès de confiance tue”, c’est le titre d’une vidéo édifiante de la chaîne Science4All (Hoang, 2020). Et ce n’est pas un titre choc, mais bien une réalité. Dans cette vidéo, l’auteur montre comment les experts mondiaux en épidémiologie étaient, massivement et avec des conséquences catastrophiques, en excès de confiance dans leurs prédictions de l’évolution de la crise du Covid-19. Soyons clairs sur le fait que ce qui était dévastateur n’était pas tant les seules erreurs de prédiction, mais surtout l’erreur dans l’évaluation de l’incertitude sur ces prédictions.
Cette histoire spécifique est spectaculaire. Cependant, il ne semble pas y avoir de raison de penser que les autres domaines soient exempts de ce problème d’excès de confiance, à des degrés plus ou moins importants. Tetlock & Gardner (2016) ont étudié pendant une vingtaine d’années la capacité des experts en politique à prédire des événements mondiaux (élections, guerre, instabilité…). Leurs données montrent que la majorité des experts, même professeurs d’université, n’étaient pas vraiment meilleurs à prédire des événements que des prédictions tirées complètement au hasard. Les caractéristiques spécifiques des quelques uns qui donnaient de bien meilleures prédictions ? Leur tendance à se remettre en question, à admettre leurs erreurs (et à en prendre l’entière responsabilité), à mesurer leur incertitude, et à mettre ainsi à jour leur carte du monde.
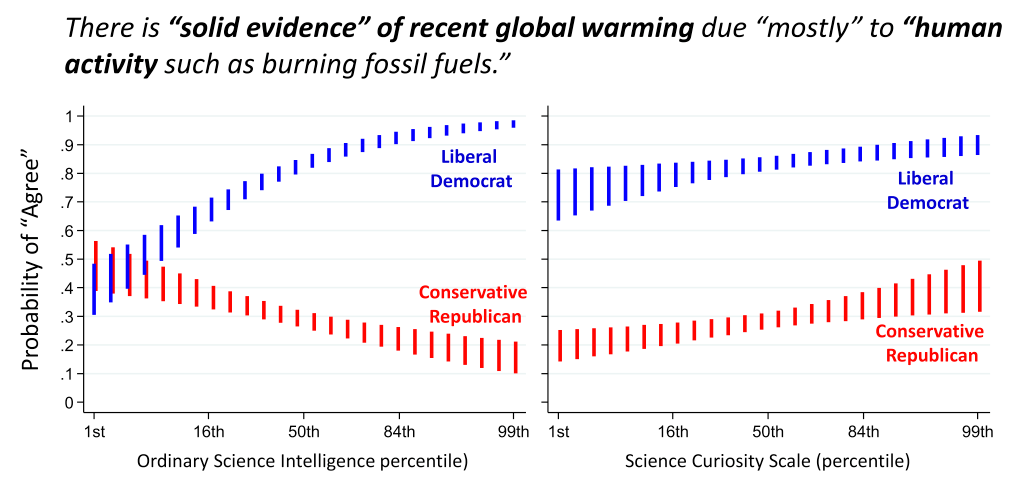
Dans la vie courante, on peut observer fréquemment, en politique et ailleurs, d’intenses débats entre plusieurs parties, chacune ayant des opinions très tranchées et chacune très certaine de la validité de ces opinions (bien qu’incompatible entre elles)… De façon fascinante, sur certains sujets politisés, l’intensité de la conviction est plus forte si la personne a une “intelligence scientifique” élevée (voir fig. 4). Et malheureusement, la voie du doute, de l’incertitude et de la mesure fait moins de bruit et se vend souvent moins bien. Cette question est explorée plus en détails dans cette conférence (Galef, 2019). L’étendue globale des dégâts de l’excès de confiance au niveau social semble difficile à mesurer, mais semble probablement forte. Et si vous pensez qu’elle est faible… Seriez-vous en excès de confiance ?
Le problème de l’excès de confiance a bien sûr des liens forts avec l’apprentissage, et on y propose une ébauche de solution avec ce projet de plateforme. Observons d’abord que notre système éducatif français ne favorise pas l’expression de l’incertitude. Admettre son ignorance est souvent mal vu. Jusque là, rien n’est en place dans le système pour valoriser une évaluation juste de notre incertitude.
Il existe une piste simple pour tenter d’y remédier, tout à fait applicable dans la plateforme. Dans les QCM classiques, vous devez sélectionner une réponse. Que vous soyez certains de la bonne réponse ou que vous n’y connaissiez rien, vous choisissez une réponse (au pire, si vous n’y connaissez rien, peut-être que vous donnerez une réponse correcte par hasard). Une proposition, du même auteur que la vidéo “L’excès de confiance tue”, est d’utiliser des QCM bayésiens (Hoang, 2019). Cette approche permet aux gens d’évaluer leur incertitude en répondant au QCM, et favorise une évaluation juste de cette dernière en utilisant un système de score adapté. Dans ce système de score, c’est lorsque votre évaluation de votre propre incertitude est bien calibrée que vous obtenez, en moyenne, les meilleurs scores. Pour le moment, les résultats de cette approche ont été très peu étudiés, mais on peut s’attendre à ce que cette approche mène à des apprentissages plus solides, qu’elle contribue à diminuer le problème de l’excès de confiance, et qu’elle favorise la métacognition des étudiants (les connaissances sur ses propres connaissances).
2.3 Implications générales
Une observation découle naturellement de ces connaissances sur le fonctionnement des apprentissages : si l’objectif est de favoriser la réussite étudiante, alors un environnement d’apprentissage, qu’il soit humain ou automatisé, cherchera à (entre autres) :
- Offrir un environnement émotionnel favorable. Notamment :
- Réduire le stress.
- Favoriser la motivation intrinsèque.
- Offrir des occasions régulières de réussite et prendre soin du sentiment d’efficacité personnelle.
- Concevoir des tâches qui génèrent du plaisir pendant l’apprentissage chez les étudiants.
- Éviter l’ennui.
- Favoriser la gestion affective des échecs.
- Offrir des questions et des entraînements de difficulté adaptée à chaque étudiant.
- Favoriser la répétition espacée, notamment en offrant des entraînements réguliers et des occasions régulières de se tester.
- Favoriser l’entraînement entrelacé.
- Favoriser une bonne calibration de l’incertitude
On ne sera pas surpris que les environnements ou systèmes qui tentent de suivre ces points obtiennent de bons résultats.
2.4 Environnements d’apprentissage intelligents
2.4.1 Un peu d’histoire
Les débuts des systèmes de tutorat intelligent (“Intelligent Tutoring Systems” ou ITS) remontent à 1970 (Carbonnell, 1970). Aujourd’hui le terme “Smart Learning Environment” (SLE) est également utilisé. Un certain nombre de méta-analyses récentes ont comparé les résultats de ces systèmes par rapport à d’autres méthodes d’apprentissage (Ma, Adesope, Nesbit, & Liu, 2014; Steenbergen-Hu & Cooper, 2013, 2014) (Ma et al., 2014; Steenbergen-Hu & Cooper, 2013, 2014).l Iressort de ces recherches que ces evironnements d’apprentissage semblent, en moyenne, plus efficaces que l’apprentissage avec enseignant en grand groupe. Il semblent également plus efficaces que l’apprentissage aidé par ordinateur mais sans environnement adaptatif, et aussi plus efficaces que l’apprentissage à partir de livres. Ils ne semblent par contre pas meilleurs que les apprentissages avec enseignant en petit groupe, ou que le tutorat individualisé.
Il y a de nombreuses approches pour créer ces environnements. De façon surprenante, l’approche à base de quiz adaptatifs (comme proposée par ce projet) n’a elle pas été très étudiée. Une étude de Ross, Chase, Robbie, Oates, & Absalom (2018) donne cependant des résultats encourageants. D’autant plus que le présent projet n’est pas seulement une plateforme de quiz adaptatifs, mais se propose d’essayer de répondre, autant que possible, aux différents points présentés plus haut.
2.4.2 Limites du projet
Bien entendu, l’idée n’est pas de proposer ce projet comme une solution miracle aux difficultés dans l’enseignement supérieur. Ce sera un outil parmi d’autres à la disposition des enseignants et des étudiants. Il pourra venir compenser efficacement la simple impossibilité pour un enseignant de s’adapter aux niveaux individuels de ses étudiants, par exemple. Mais il ne pourra pas du tout répondre, entre autres, au simple besoin de contact humain des étudiants, ou se comparer à la grande richesse que peut apporter un enseignant pédagogue.
3 Expérience utilisateur
3.1 Étudiants
L’étudiant se connecte à la plateforme et a la possibilité de s’entraîner sur des quiz créés par ses enseignants. Pour la première version, les questions sont au format QCM à 4 réponses. Il y a plusieurs différences majeures par rapport à l’existant (Moodle par exemple) :
Plutôt qu’un parcours de quiz prédéfini, l’étudiant se voit présenter des questions et des challenges adaptés à “là où il en est” (son niveau, par exemple, mais pas exclusivement). En conséquence, il est stimulé intellectuellement, mis au défi par des questions légèrement au-dessus de son niveau actuel, et cela favorise sa motivation à s’entraîner, et donc sa progression. Les questions trop faciles pour son niveau actuel sont évitées de façon à ce qu’il ne s’ennuie pas, et les questions trop difficiles sont évitées de façon à ce qu’il ne se sente pas découragé. En coulisses, le système utilise des algorithmes pour tenter de déterminer la valeur de différentes variables latentes (« Latent Variable », n.d.) associées à l’étudiant. Cela peut être principalement son niveau dans la matière, mais peut-être aussi dans une version ultérieure, sa fatigue à un moment donné par exemple, ou son style d’utilisation de la plateforme… En somme, ce qui peut être pertinent pour que le système s’ajuste et accompagne efficacement l’étudiant dans sa session d’entraînement.
Dans de nombreux domaines, certaines questions sont simplement des choses à mémoriser. Plutôt que de laisser au hasard le fait que l’étudiant ait eu la chance ou non d’apprendre des techniques de mémorisation efficaces, le système va l’aider : la courbe de l’oubli (fig. 2) est connue depuis longtemps. Le système va donc s’en servir pour présenter les questions de mémorisation de façon répétée, à intervalles temporels intelligents.
L’étudiant peut s’immerger dans le système, qui est conçu spécifiquement pour qu’il s’entraîne au mieux. L’interface est épurée, très réactive, et tout est conçu pour favoriser sa concentration lors de sa session d’entraînement. À la différence de Moodle (par exemple), qui poursuit des objectifs plus larges (intégrations de nombreux modules, gestion des groupes, documents, examens en ligne…), la plateforme se veut être un outil externe dédié et optimisé pour s’entraîner.
Dans les versions ultérieures, il est prévu de rajouter des fonctionnalités facilitant les interactions entre les utilisateurs : par exemple sur la page d’une question du quiz, l’étudiant pourra indiquer qu’il n’a pas compris les explications, ou poser une question supplémentaire (que l’enseignant pourra éventuellement utiliser comme base pour intégrer une nouvelle question dans le quiz). Pourrait s’ensuivre une discussion, par question, entre étudiants et enseignants, enrichissant et approfondissant le sujet.
3.2 Enseignants
Dans la première version, l’enseignant peut déposer des banques de questions sur la plateforme à partir d’un fichier CSV. Les quiz de la première version seront au format QCM à 4 choix possibles, avec une seule bonne réponse.
Dans les version suivantes, l’enseignant pourra utiliser la plateforme de façon beaucoup plus riche :
Il pourra accéder à des statistiques lui indiquant les questions qui sont les plus mal comprises, les plus difficiles, les plus faciles… Comme il n’est pas toujours facile pour l’enseignant de se construire une représentation claire du niveau, des besoins et des lacunes de ses étudiants (en particulier avec la crise sanitaire), ces statistiques pourront l’aider dans cette démarche.
Il pourra interagir avec avec les étudiants sur les mini-forums associés aux questions, pour par exemple apporter des clarifications, des liens vers des documents permettant d’approfondir, encourager ses étudiants sur les questions difficiles…
Il pourra facilement ajouter de nouvelles questions aux quiz, directement sur le site web. Au fur et à mesure du développement du moteur adaptatif, d’autres formats de questions que le QCM à 4 réponses seront possibles. L’enseignant aura ainsi un choix progressivement plus flexible dans les types de questions et de contenu qu’il peut créer sur la plateforme.
3.3 Intégration avec l’existant
Cette plateforme interagit facilement avec l’existant au sein d’AMU, en particulier avec Moodle. C’est cependant un outil externe, clairement séparé de Moodle. Cela permet d’éviter la dépendance à une plateforme particulière de gestion des apprentissages comme Moodle, et permet d’envisager que cet outil soit utilisé dans d’autres universités.
Concrètement, l’intégration avec Moodle se fait par le biais du protocole LTI (Learning Tools Interoperability) (IMS Global Learning Consortium, 2019; Severance, 2009).
4 Implémentation technique
4.1 Première version
4.1.1 Aperçu de l’architecture logicielle
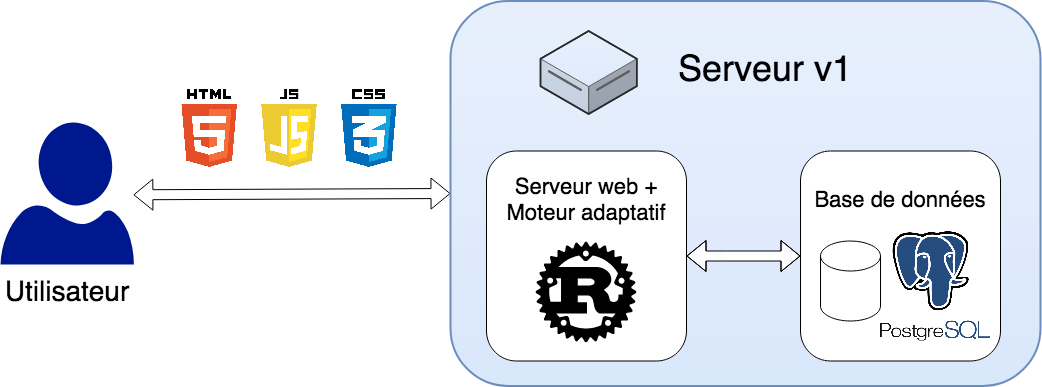
L’architecture logicielle de la première version est relativement simple : elle comporte principalement un serveur web écrit en Rust, une base de données PostgreSQL (PostgreSQL Global Development Group, 1996), et un moteur adaptatif (qui a pour tâche de sélectionner les questions à poser à l’étudiant).
Plus précisément, le serveur web utilise le framework Actix (Kim, 2017), un des framework web les plus performants au monde (Tech Empower, 2019), tout en étant d’une utilisation très ergonomique.
PostgreSQL est un moteur de base de données relationnel open source, dont la plateforme peut tirer profit des fonctions spécifiques : PL/pgSQL (PostgreSQL Global Development Group, 2021a), Row Level Security (PostgreSQL Global Development Group, 2021b)…
Le moteur adaptatif utilise principalement une variation du système de classement Elo (« Classement Elo », n.d.; Elo, 1987) adaptée pour le cas présent (sélectionner les questions de difficulté correspondant au niveau de l’étudiant). Cet algorithme est décrit avec plus de détails plus bas. Le moteur adaptatif est ici simplement intégré directement au serveur web (il sera plus tard rendu modulaire, de façon à pouvoir intégrer facilement plusieurs algorithmes).
4.1.2 Besoins en termes d’infrastructure
Les besoins en calcul de la première version sont faibles, et le nombre d’utilisateurs sera au début relativement limité. Ainsi, une machine virtuelle derrière un reverse proxy, comme HAProxy (Tarreau, 2001), sera certainement suffisante. Cette version étant davantage une première expérimentation pour recueillir des retours utilisateurs et tester l’efficacité des algorithmes, la redondance n’est pas une priorité absolue. La suggestion est donc d’ajouter la redondance ultérieurement. L’architecture proposée pour la version 1 est résumée par la fig. 5.
4.2 Anticipation des besoins futurs
Il est attendu qu’après la première version, la plateforme évolue rapidement, dans trois directions principales :
- Ajout progressif de fonctionnalités pour les utilisateurs, comme les fonctionnalités discutées plus haut pour les enseignants.
- Montée en charge progressive au niveau du nombre d’utilisateurs et du temps passé par utilisateur sur la plateforme, amenant à des exigences de haute disponibilité (discutées plus bas).
- Intégration d’algorithmes adaptatifs plus intelligents et plus complexes, prenant avantage des données générées par les utilisateurs. Ces algorithmes seront notamment à base de deep learning (« Apprentissage Profond », n.d.).
Ce troisième point amène naturellement à l’anticipation d’un besoin spécifique différent des projets web conventionnels : l’entraînement efficace de modèles de deep learning nécessite des GPU (Graphics Processing Unit ou carte graphique) puissants, adaptés aux besoins de calculs massivement parallèles de ces modèles et de leur boucle d’entraînement.
4.2.1 Entraînement de modèles d’IA sur GPU
En fonction de la tâche, de la nature des données et du matériel spécifique, le gain de performance GPU contre CPU pour l’entraînement de modèles est généralement de l’ordre de 5 à 50, comme élaboré dans cet article (DATAmadness, 2019), cet article (Lazorenko, 2017), ou encore cet article (Mooney, 2020). Il existe quelques cas particuliers où l’entraînement sur CPU est en fait plus rapide, ici par exemple (« Choosing between CPU and GPU for training a neural network », 2017), mais ils sont plutôt rares, et on s’attend à ce que les tâches d’entraînement utilisées pour la plateforme bénéficient fortement de l’utilisation de GPU.
Cela dit, il n’est pas question d’un besoin d’une large ferme de GPU utilisés en continu pour les seuls besoins de la plateforme. Il semble probable qu’un seul serveur, dédié à l’entraînement et disposant de 4 à 8 GPU puissants, soit suffisant pour couvrir tous les besoins d’entraînement de la plateforme pour AMU.
4.2.2 Inférences des modèles
Après l’entraînement et le réentraînement des modèles (mise à jour à mesure que de nouvelles données sont générées par les utilisateurs), les modèles sont utilisés par la plateforme pour faire des prédictions et s’adapter au mieux à l’étudiant. Le terme utilisé en machine learning pour ces prédictions est “inférence”.
De façon contre-intuitive, il est souvent préférable de faire les inférences sur CPU (Central Processing Unit ou processeur) plutôt que GPU : lors de l’entraînement, on s’appuie sur l’architecture parallèle du GPU pour lui envoyer de nombreus éléments de données à traiter en parallèle. Lors de l’inférence, on a en général un seul élément de données (représentant l’action d’un utilisateur par exemple). Et dans ce cas de traitement d’élément individuel, la latence de calcul est souvent plus faible en utilisant le CPU. Pour le dire autrement, sur GPU la latence est plus élevée mais la bande passante est aussi largement plus élevée (fort avantage pour l’entraînement), alors que sur CPU la latence est plus faible mais la bande passante aussi plus faible (avantage pour l’inférence).
Un avantage de cette approche est que pour assurer la haute disponibilité du service, le serveur d’entraînement des modèles ne nécessite pas d’être redondant. En effet, il peut entraîner les modèles de façon asynchrone et envoyer les dernières versions sur les backends web, qui s’en serviront pour l’inférence.
4.2.3 Redondance
On peut anticiper une montée en charge progressive et une exigence de haute disponibilité du service. Pour proposer une architecture répondant à ces besoins, partons de quelques points :
Gestion de la charge : D’une part, à la différence des charges typiques d’Ametice, qui subit régulièrement des pics de connexions simultanées (au moment du début d’un examen par exemple), on s’attend ici plutôt à une charge plus continue et “étalée”, avec des pics plus rares. D’autre part, l’application serveur sera très performante (car écrite en Rust (Matsakis & Klock, 2014), un langage compilé). Il semble ainsi qu’une seule machine virtuelle (VM) modérément puissante, et contenant toute l’architecture logicielle (afin de minimiser la latence) soit suffisante pour gérer la charge attendue, même en imaginant tous les étudiants AMU utilisant la plateforme simultanément. On estime ainsi que du load balancing ne sera probablement pas nécessaire pour tenir la charge à l’échelle d’AMU. Cela permet de simplifier l’architecture.
Haute disponibilité : Le fait que du load balancing ne soit pas nécessaire ne résoud pas le besoin de haute disponibilité. Pour répondre à ce besoin, la proposition est d’utiliser 2 serveurs virtuels identiques et redondants : un primary et un warm standby répliquant le premier, prêt à prendre le relai à tout moment. Les deux serveurs font tourner la pile logicielle complète (dont la base de données PostgreSQL). La base de données est répliquée du primary vers le warm standby. Comme cette application peut tout à fait tolérer une perte de données de l’ordre d’une seconde en cas de panne, la réplication peut même se faire de façon asynchrone. Plus précisément, le mode de réplication de PostgreSQL asynchronous streaming replication semble être un excellent compromis ici, permettant au standby d’avoir un retard minimal sur les données, tout en minimisant également la latence des transactions sur le primaire.
Sur les serveurs web, le moteur adaptatif s’appuiera sur des modèles générés par le serveur d’entraînement (contenant les GPU), mais il n’est pas nécessaire que ce dernier soit redondant pour la haute disponibilité du service. Cela est dû à la nature du cycle d’entraînement : périodiquement, les données sont poussées sur le serveur d’entraînement, les modèles sont entraînés, puis récupérés par poussés les deux backends web répliqués, qui les utilisent localement pour leurs prédictions. Il est important de réentraîner les modèles régulièrement avec les dernières données pour que le système soit performant, mais une interruption de quelques heures du serveur d’entraînement n’est pas catastrophique. Cela permet de réduire notablement le coût total de l’architecture, puisque les serveurs avec GPU sont particulièrement coûteux.
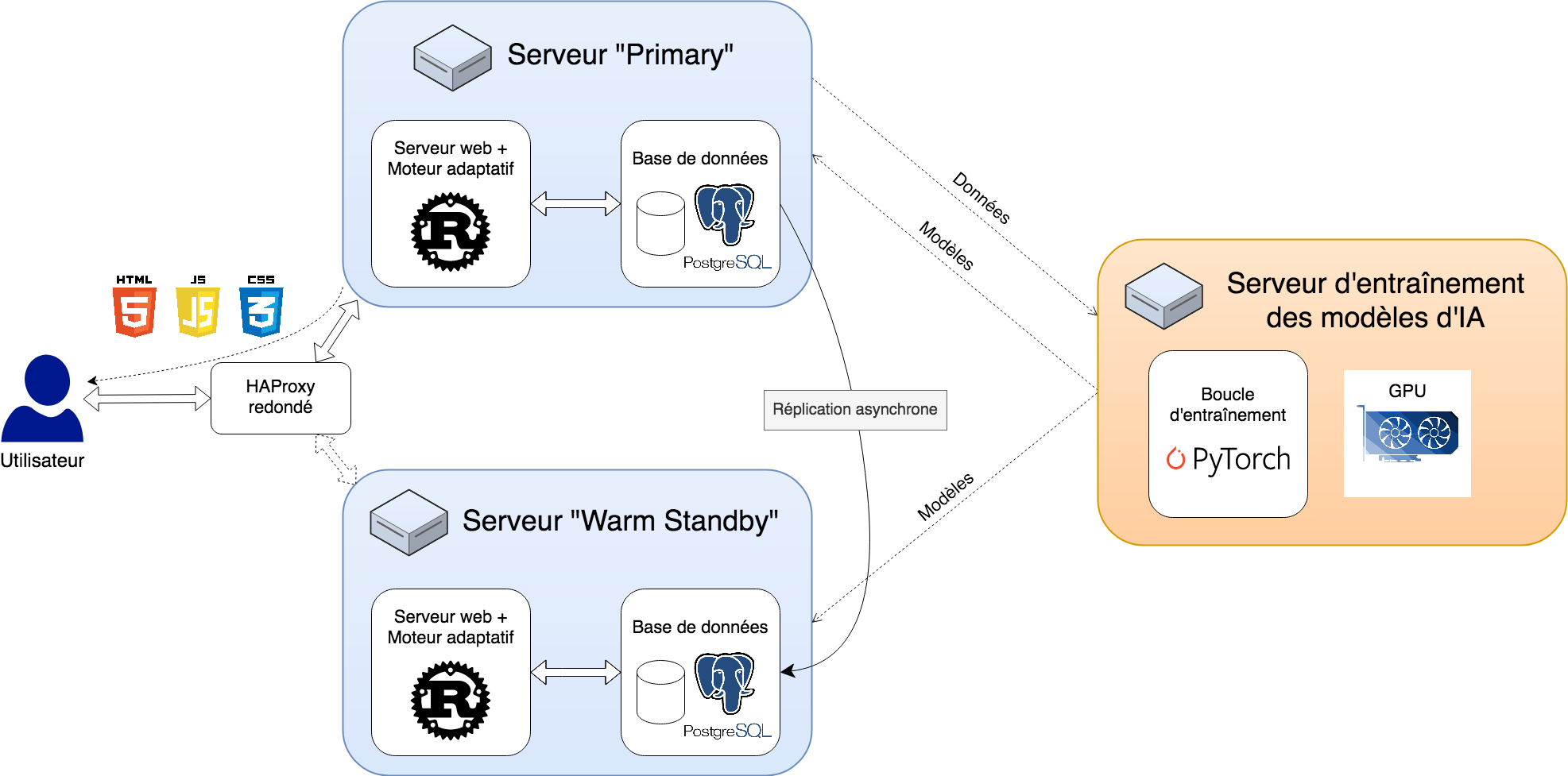
Cette architecture, où chacun des deux serveurs web exécute la totalité de la pile logicielle, a plusieurs avantages :
- En termes de performances, le temps de traitement total d’une requête est minimisé, puisque la totalité du traîtement se fait sur la même machine (pas d’accès réseau nécessaire, optimisation des accès cache).
- En termes de fiabilité, il n’y a aucun point de défaillance unique : n’importe lequel des composants sur le diagramme peut subir une panne, cela n’entraîne pas l’arrêt du service.
- Cette architecture est relativement simple, ce qui facilite la compréhension et la maintenance du système.
5 Aperçu des algorithmes
Cette section tente de donner un apeçu clair du fonctionnement général des algorithmes utilisés par la première version de la plateforme. Ces algorithmes sont voués à évoluer vers d’autres algorithmes plus performants au fur et à mesure de la vie de la plateforme, des données générées dessus, et de l’avancement de la recherche dans le domaine.
5.1 S’ajuster à la zone proximale de développement
Pour sélectionner des questions de niveau adapté, le premier algorithme qui sera utilisé est une variante du système de classement Elo (« Classement Elo », n.d.; Elo, 1987). Ce système a été développé, au départ, comme un système de point reflétant la compétence générale des joueurs d’échecs. On peut visualiser ce système comme suit : imaginons deux joueurs, Alice et Bob. Ils font une partie ensemble, et on a bien sûr deux issues possibles : Alice gagne, ou Bob gagne. Disons pour commencer qu’avant la partie, Alice et Bob avaient chacun un score Elo de 2500 points. À l’issue de la partie, les scores sont alors mis à jour comme dans la fig. 7. Si Alice gagne, son score Elo augmente ici de 20, et le score de Bob descend de 20. Inversement si Bob gagne.

Par contre, si les scores de départ sont très différents (par exemple 3000 pour Alice et 2000 pour Bob), les choses se passent autrement. Comme les scores Elo se veulent refléter la compétence des joueurs, on s’attend à ce qu’Alice gagne la plupart du temps, puisqu’elle a un score bien plus élevé que celui de Bob. Alors, si effectivement Alice gagne (le résultat probable), les scores sont mis à jour, mais avec un changement très faible : Alice gagne ici 4 points, et Bob en perd 4. Par contre, si Bob gagne (le résultat inattendu), alors il y a une mise à jour plus forte des scores : Alice perd ici 112 points, et Bob en gagne 112 (fig. 8).

En effet, il est important que Bob gagne de nombreux points s’il gagne alors qu’il était considéré comme beaucoup moins compétent qu’Alice avant la partie : peut-être qu’il a eu un coup de chance à cette partie, mais peut-être aussi qu’il s’est beaucoup entraîné depuis leur dernière rencontre. Il serait alors maintenant capable de gagner plus souvent contre Alice. C’est un des avantages de cet algorithme : de façon “organique”, pragmatique, les scores convergent rapidement pour refléter avec justesse les niveaux relatifs de compétence des personnes. De plus, les scores n’ont rien de statique, dans le sens où ils sont une mesure de la compétence à un instant donné, vouée à évoluer au fur et à mesure que la personne progresse.
Un énorme avantage pratique de cette approche est de pouvoir facilement sélectionner des adversaires à son niveau, des adversaires avec qui la partie va être palpitante, stimulante, et va toucher notre zone proximale de développement. Une partie contre un adversaire 1000 points au-dessus ou en-dessous de vous sera ennuyeuse et ne vous apprendra probablement pas grand chose.
De notre côté, on ne cherche ici pas à faire des matchs d’étudiant contre étudiant (bien que l’idée de “duels” peut aussi être motivante et vaut le coup d’être explorée). La première idée de la variante est donc, plutôt qu’étudiant contre étudiant, de faire des match d’étudiant contre question (fig. 9). On va donc, en fonction du score actuel de l’étudiant, lui proposer une question dans la proximité de ce score.
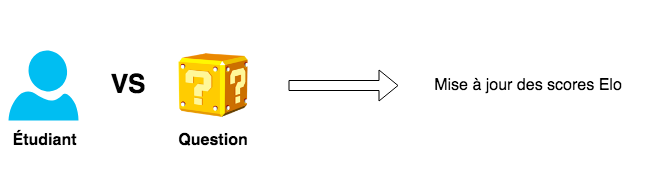
Voilà l’idée de départ. Cependant, on peut pressentir quelques problèmes si on applique la simple approche Elo dans ce cadre. En particulier, si les étudiants peuvent s’entraîner et progresser, les questions, elles, sont statiques. On pourrait attribuer, manuellement, un score statique à chaque question avant qu’elle entre dans le système. Ce serait bien dommage :
- Il n’est pas évident pour un enseignant de mesurer très finement la difficulté réelle d’une question pour ses étudiants.
- Ce serait plus de travail pour les enseignants.
- On perdrait l’opportunité de mesurer automatiquement la difficulté des questions.
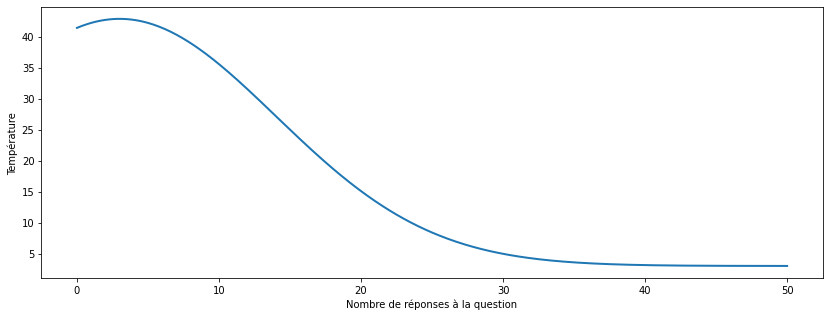
On a donc besoin d’un ajustement supplémentaire, et la proposition et la suivante : la température des questions. Au début, quand une question n’est peu ou pas connue du système, elle sera “chaude”. À chaque match face à un étudiant, son score sera fortement mis à jour, pour essayer de déterminer rapidement sa difficulté générale. Petit à petit, à force des matchs, la question refroidit et son score évolue de moins en moins, jusqu’à être quasi fixe (fig. 10). Ce processus est analogue à un métal chaud facile à déformer, et qui refroidit progressivement, stabilisant sa forme finale.
On peut apporter une critique à cette famille d’approche : depuis le début, on discute un peu comme s’il était avéré qu’il y a un “niveau” de l’étudiant dans une matière (représenté par le score Elo), et que ce seul niveau est un bon prédicteur de ses réponses aux questions. C’est probablement une bonne approche générale, mais par exemple, on peut être bon en algèbre et mauvais en géométrie… Dans ce cas, un seul score représentant “les maths” est-il suffisant ? On peut probablement faire plus fin, et c’est prévu dans les itérations ultérieures de la plateforme. Notamment, des chercheurs ont récemment proposé un système de score Elo multidimensionnel (Prisco et al., 2019; Zaffalon et al., 2020). On peut envisager cette approche, ou d’autres à base de réseaux de neurones par exemple (probablement les plus puissantes au long terme).
5.2 Offrir un environnement émotionnellement favorable
Pour offrir un environnement émotionnellement favorable à l’apprentissage, une attention particulière sera portée dans le design et le comportement de la plateforme pour qu’elle ne soit pas stressante, qu’elle soit ergonomique, réactive et immersive (idéalement, l’étudiant oublie qu’il est sur un site web et se concentre sur ses apprentissages et son entraînement). La sélection des questions se fera de façon à ce que l’étudiant fasse régulièrement l’expérience de succès avec des bonnes réponses. On tentera de garder les étudiants motivés, notamment par le biais des feedbacks aux questions et des interactions possibles sur la plateforme.
5.3 Faciliter la répétition espacée
Pour favoriser la répétition espacée, on peut réutiliser l’approche de l’application Anki : globalement, à chaque rappel correct de la question X, on augmente l’intervalle avant la prochaine présentation de la question X, en multipliant par exemple l’intervalle précédent par 2. En réalité, l’approche d’Anki est un peu plus avancée. Mais il y a encore mieux : Tabibian et al. (2019) ont montré que si nos modèles de la mémoire humaine ne sont pas trop faux, il y a en fait une stratégie optimale. Pour chaque information à mémoriser, modéliser sa probabilité de rappel par l’étudiant, et utiliser cela comme base pour programmer une révision de l’information. À chaque fois que, selon notre modèle, la probabilité de rappel passe en dessous d’un certain seuil (80 % par exemple), il est temps de représenter la question.
5.4 Faciliter la pratique entrelacée
Pour faciliter la pratique entrelacée, c’est très simple : au lieu de pouvoir seulement réviser par matière, l’étudiant aura la possibilité de faire des révisions “globales” (avec tous ses enseignements), ou des révisions “mixées” (avec plusieurs matières sélectionnées). Les questions qui lui seront posées seront alors tirées de toutes les matières incluses dans la révision, de façon à optimiser l’entrelacement.
5.5 Favoriser la gestion de l’incertitude
Pour combattre l’excès de convaincre et favoriser une calibration juste, la méthode des QCM bayésiens (Hoang, 2019) sera utilisée principalement. Concrètement, au lieu de sélectionner la réponse qui semble correcte, l’étudiant pourra indiquer son niveau de confiance dans les différentes réponses proposées grâce à des “sliders” ergonomiques.
5.6 Favoriser les bonnes habitudes d’apprentissage
La plateforme tentera d’agir au mieux avec les stratégies décrites plus haut pour favoriser l’apprentissage. Cependant, il pourrait aussi être utile pour les étudiants d’avoir accès à une ressource regroupant les astuces et connaissances scientifiques pour améliorer ses apprentissages, dans un format pédagogique. Cela leur permettrait de les découvrir ou les redécouvrir, et de les appliquer s’ils le souhaitent, dans leurs autres apprentissages. Ce serait la “boîte à outils” de l’étudiant, qui pourrait être facilement accessible sur la plateforme.